





以下为思码逸创始人兼 CEO 任晶磊在“AES 智能体工程峰会”中的演讲实录。文末扫码可下载演讲 PDF。
大家好。非常高兴参加 AES,也很高兴能跟各位一起迎接「人人都是技术管理者」的时代。
先简单介绍下思码逸。我们从 2018 年开始创业,专注于用程序分析技术来度量软件研发效能。在 AI 新浪潮下,我们为客户提供研发数字化+研发智能化的整体解决方案。
我们团队今年制定了一个很明确的目标:研发不再写一行代码。既包括新开发的软件,也包括过去的那些老旧系统——怎么一块一块地把它们规约化、重构成 AI Native 的形态。今天我会分享一些团队的实践经验。
今天主要分享三个部分:
AI 原生软件工程的三个回归
DevData 2026 基准数据洞察
AI 原生软件工程的可观测性
三个回归
回归本质目标:如何让 Agent 成为主力
现在大家看 Twitter 或者国内公众号文章,有大量这样的案例:半小时实现一个 UI、两小时搭一个后端、一天做一个 APP。
但是我们想一下,“干得快”真的是软件工程的核心目标吗?我个人认为它最多只能算一个方面。本质上,软件是一种服务,快速实现某个切面上其实没那么重要。一个项目主要的壁垒和竞争力在于能否持续维护。
所以,AI Native 软件工程的目标可以总结为一句话:让 agent 自主、可靠地持续交付有价值的工作。
拆解一下这几个关键词。
1、自主。 假设一个 agent 每分钟找你一次,另一个 agent 能在用户不干预的情况下持续干三个小时,你会选哪个?我想后者总体效能会更好。这不仅意味着支撑它持续工作的工程基础更强,也意味着你自己真的省心省力。
2、可靠。 我们都希望智能体在工作中又准确、又有鲁棒性。这意味着仅仅在一两个任务上表现得聪明是不够的,它必须要持续靠谱。
3、有价值。这也是一个显而易见的、我们期待的属性。
所以,Harness Engineering 的核心,就是面向可靠性去构建整个 agent 系统。
回归本质路径一:SDD 范式
未来的软件开发,人类工程师工作的对象不再是代码,而是 spec——你和代码之间、和系统之间的某种规约。
关于怎么写 spec,人们普遍有两种做法。
在一端,把所有东西写在 prompt、PR、issue 里,这时候 spec 解决的是「我怎么把需求表达清晰」的问题。但这里存在一个难点:这些 spec 后续怎么留存和管理,如果任由其增长,长期可能会失控。
在另一端,业界有了 Spec Kit 和 OpenSpec 这样的框架来对 spec 进行管理。但真正用过的人应该都跟我感同身受——整个流程太重了。干个什么事要很多操作,生成的 spec 也很长。再加上我们不是英文母语,有时候完全没有耐心去看完。所以后来我自己也放弃了这套流程。
那么我们怎么做的呢?我的建议是在两端之间找一个合适的位置。
遵循两个原则:第一,不干预现有的流程;第二,不重复造轮子。
在这样的原则下,我们的做法是「反过来」——不限制流程,但规定好一些最基本的动作,在这些动作里把 spec 存留好或使用 spec,这样就够了。这个对大家的负担更轻。基于这些「原语」怎么自由组合使用是开发者个人的选择,不做过多限制。
那这些最基本的动作有哪些呢?我们可以用“DIG”这三个字母来快速记忆:
D(Decision):决定。无论考虑架构还是一个具体的设计,我们每天做软件的过程中都在做大大小小的决定,要把它们写在 spec 里,这里推荐 ADR 格式,它在业界已经有很多年的积累,有社区组织、有标准,值得信赖。
I(Iteration):迭代。这块儿业界没有统一格式,我认为要在过程中关注四个要素:这个 Iteration 的目标是什么?要交付哪些产物?要完成哪些任务?最后验收准则是什么?
G(Generation):生成。这是 spec 的大头,格式同样不需要重复造轮子,推荐直接用 EARS。这是 2009 年在需求工程大会上产业界提出的一种 spec 格式;到 2019 年,这篇论文还获得了十年最具产业影响力论文奖。所以它的表达能力和适用性都不用担心,直接拿来用。我们稍微做了一点扩展,在前面加了个 “G”,综合成 GEARS 格式。因为 EARS 原始定义是给人看的,有各种 pattern,人理解起来容易,但喂给大模型交互的时候 token 消耗比较大,大模型也未必能完全理解正确,所以我们在此基础上做了一层抽象,全部统一成如下语法:
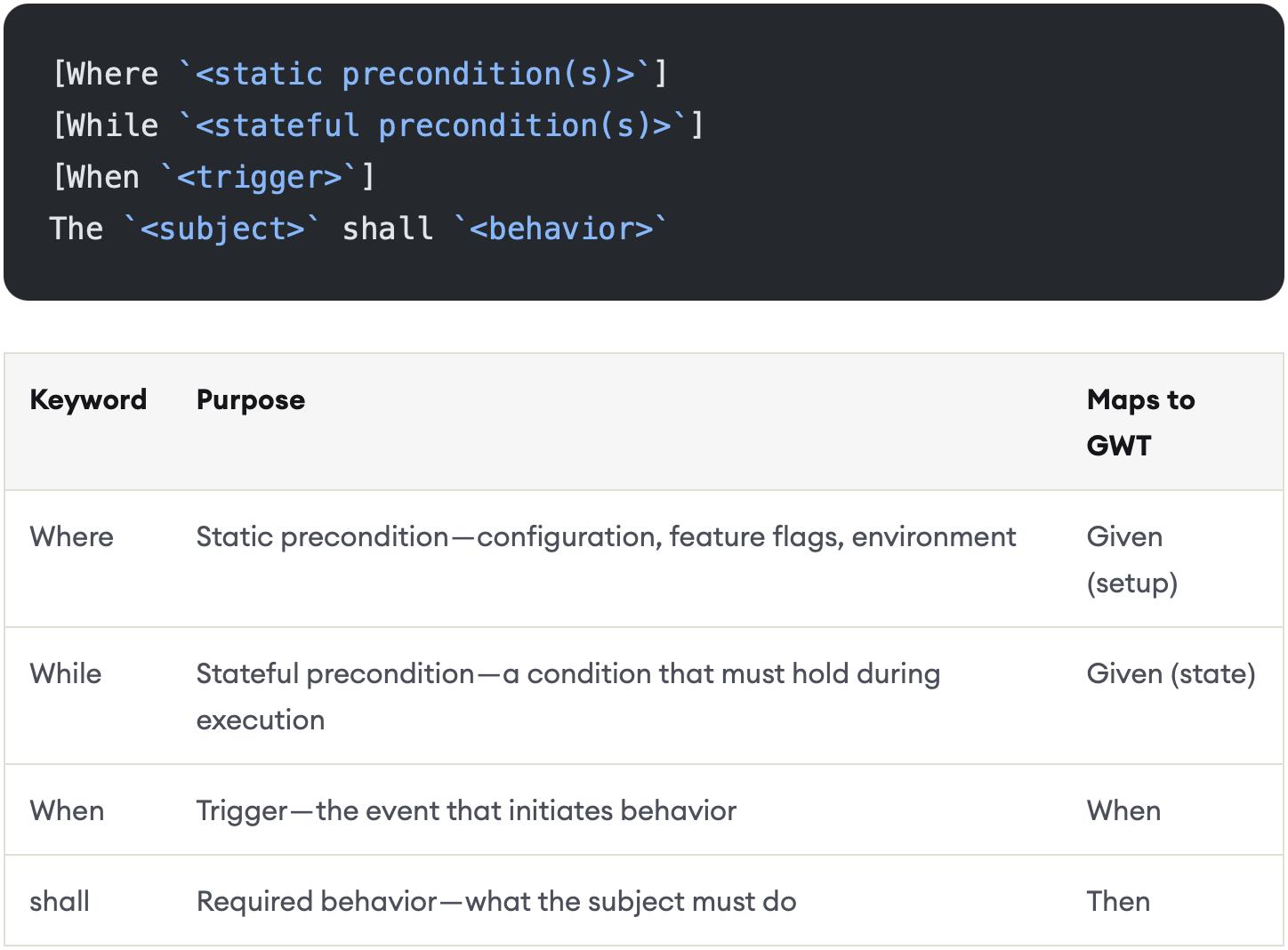
举个例子,比如为文件添加 copyright 头的功能。如果你只把这一句话给大模型,表述里有很多模糊的地方,自然难以实现到位。但按 GEARS 格式表达,就准确很多:
Where the file has comment syntax,
while the file is git-tracked,
when the file is updated,
the licensor shall add SPDX-FileCopyrightText to the file.
Where(属性):这个文件首先得有 comment 语法,你不能上去改它实质的内容,因为加 copyright 只是添加了一个注释。
While(状态):这个文件必须在 Git 里被 track,如果压根没放进去,可能是临时文件,加 copyright 头没有意义。
When(条件):当这个文件被更改时触发,别一上来把整个库里文件全部改了。
加上这些行为约束之后,需求本身表达得就非常清晰了。这就是 spec 条目化的意义。spec 的主体形态就是由这样一个个规范化的条目构成。
回归本质路径二:Agent 可控性
另一个在实现路径上的回归——怎么控制 agent。
核心矛盾是「一管就死,一放就乱」,跟人的组织管理其实一样。管太死,agent 的能力发挥不出来;完全放开,它有时候就放飞了。
对于这两端,我们也有一些既有的做法。比如用 Dify、n8n 把整个流程表达出来,虽然可以加智能分支,但总体而言比较固化,做的成本高,后续维护成本也高。当然,某些场景下肯定还是适用的。
另外一种方式就是写 skill,有人宣称 skill 是未来的应用形态。这在一定范围内是成立的。但真的长时间跑一个任务,单纯用 skill 的话,agent 经常放飞,或者走到你不想让它去的方向上。这个“锅”有时候不是 AI 的,而是因为 skill 是用自然语言写的,里面很有可能会有一些模糊的点、没考虑到的情况。
所以我们的「回归」同样是在两端之间找一个更合适的点。我们做了一个工具叫 Playbook 来实现:
第一,还是用自然语言表达——你希望干什么事,像 skill 那样把它表达出来。
第二,把 skill 转成状态机。状态机的好处在于它是完整的、有限状态的。自然语言是一个开放空间,但放在状态机里跑,就是一个有限的集合,它只能在这个圈里跑。状态不够可以加,不明确可以让 AI 对话;但最后状态机定下来,它就只能在这个范围内跑。
表达 skill 或者 playbook 的自然语言,跟管一个团队分任务其实是一样的。所以我们说,现在是一个「人人都是技术管理者」的时代。你去表达一个流程,很多时候也是把一个事分给几个 agent 去干。
AI 原生转型:回归本质
前面这些技术和流程上的选择,我觉得没有什么特别的地方,就是回归常识,回归本质。
在座各位都是软件工程领域的“老炮”了,在 AI 时代,我们自己的经验、判断其实是更加重要的。今天我们每天被各种文章轰炸,加上现在 AI 供给这么充足,必然会有各种市场声音,其实很多背后也是为了 Go-to-Market。在这种情况下,更重要的是能够看透这些新概念,所谓 spec 怎么写、流程怎么控制,后面其实就是最基本的判断,我们不用太过焦虑。






 在线客服
在线客服












